OpenCode Ollama GLM Test
지난번 글 에서 qwen3-coder 를 테스트 해 보고 처참한 결과를 내었는데, 이번엔 좀 더 성능이 괜찮다고 하는 GLM-4.7 을 테스트 해 보기로 했다.
지난 번 것에 이어서 진행한다.
보면 알겠지만 기본 모델 목록엔 이번에 사용할 glm-4.7-flash 가 없다. 하지만 ollama 모델 저장소에 없는 것은 아니다 
그냥 이름을 복사해서 붙여넣으면 마치 원래 있었던 것 처럼 나타난다. 
모델을 선택 후, 지난번과 마찬가지로 아무 내용이나 타이핑 하면 download 가 시작된다 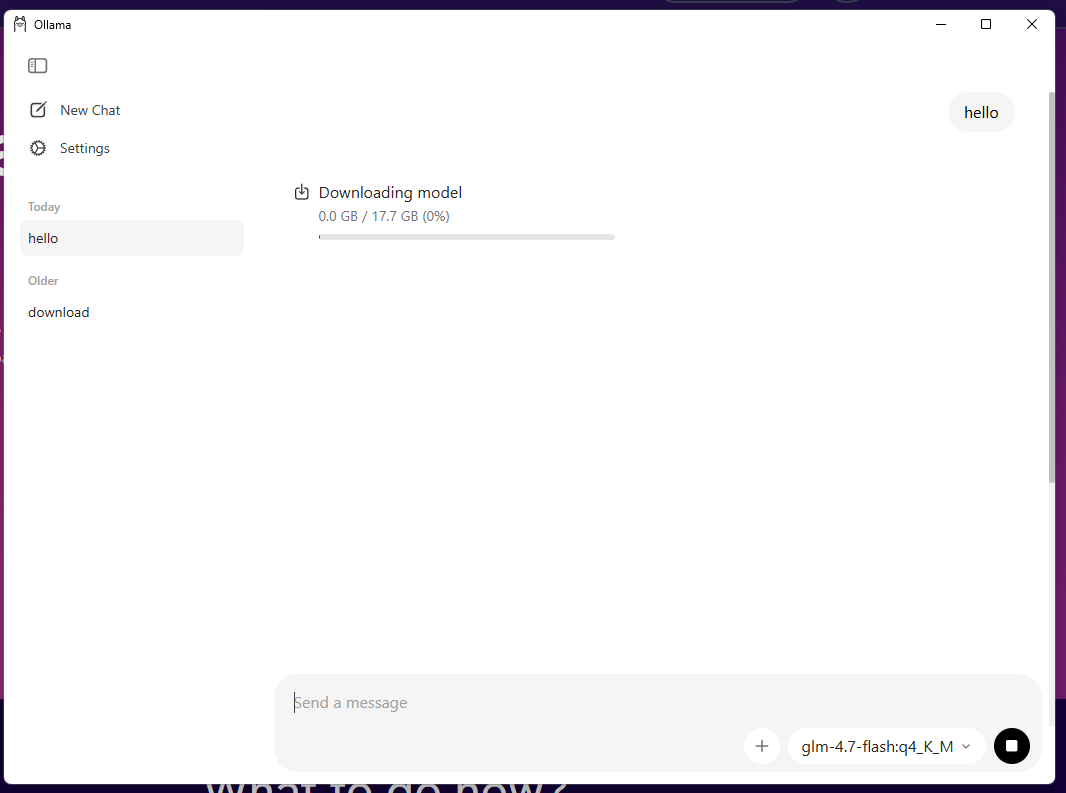
이전에 만들어 둔 opencode.json 를 열고 다음과 같이 수정 한다. glm-4.7-flash:q4_K_M 모델을 추가 하는 것 뿐이다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"ollama": {
"npm": "@ai-sdk/openai-compatible",
"name": "Ollama (local)",
"options": {
"baseURL": "http://localhost:11434/v1"
},
"models": {
"qwen3-coder:30b": {
"name": "Qwen3 Coder 30B"
},
"glm-4.7-flash:q4_K_M": {
"name": "GLM 4.7 Flash 30B"
}
}
}
}
}
opencode 를 실행 후, /model 을 입력하여 이번에 추가한 local 모델을 선택 해 준다. 이것으로 세팅이 완료된다 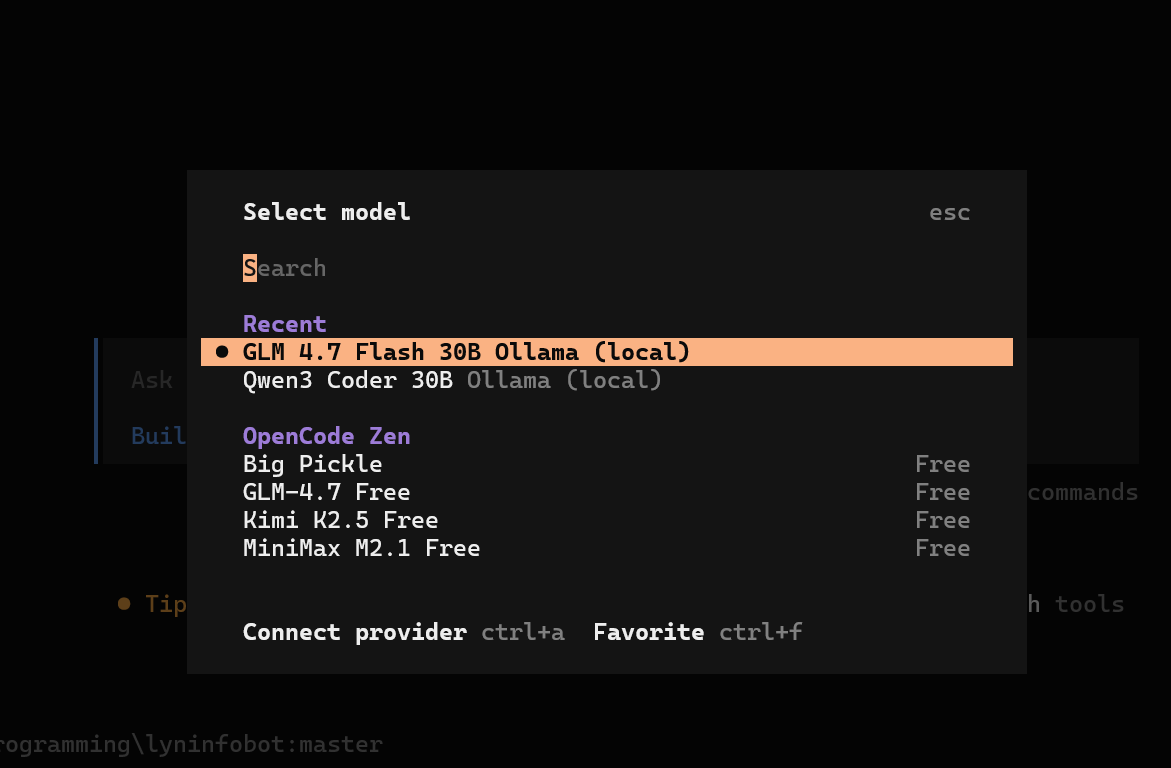
같은 30B 급 모델이라 Context Size 별 VRAM 소모는 저번에 테스트한 qwen 과 다르지 않다 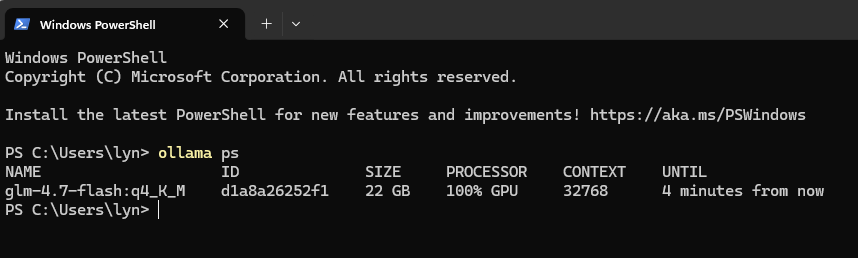
저번에 테스트 해 본 프로젝트로 같은 import 빠진 것 이슈는 빌드 한번 해 보더니 금방 찾아 냇다. 그래서 다른 테스트를 해보기로 한다. var 로 선언 되어야 할 mutable 변수를 val 로 선언해 본다. 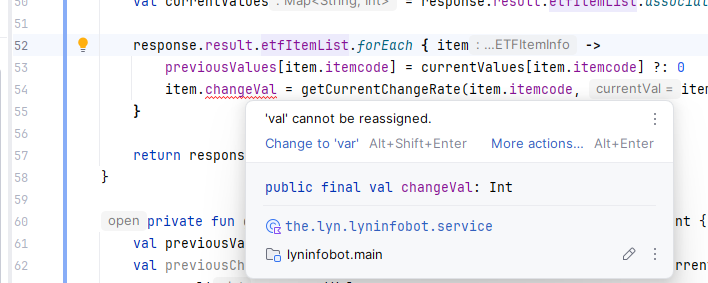
일단 몇번의 빌드를 시도 하더니 원인을 금방 찾아 내기는 했다. claude 보다는 좀 여러번 리트라이를 하는 느낌은 있었지만 일단 되었다는것에 만족한다.
그래서 간단한 기능 추가를 시켜 보기로 했다. 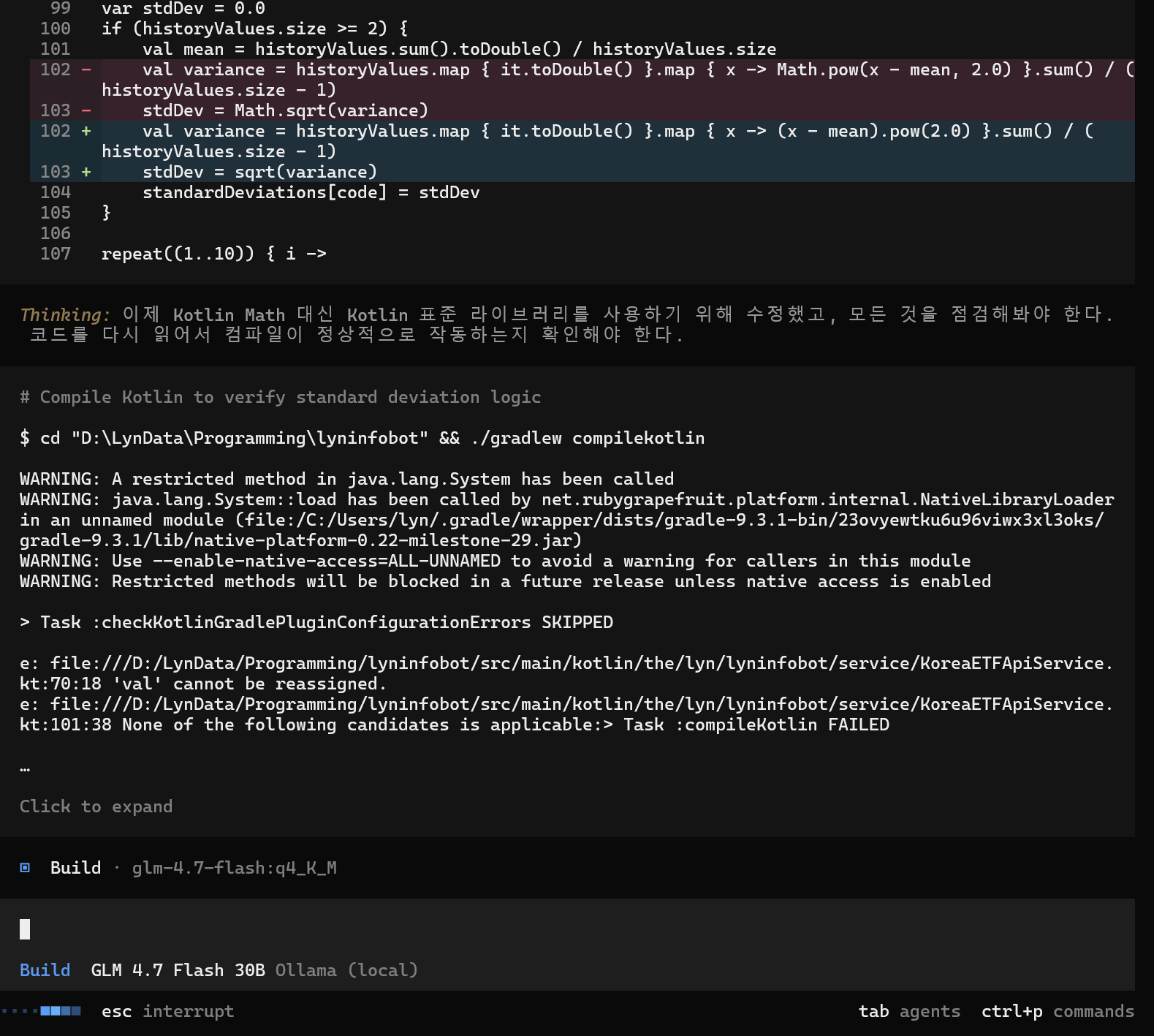
코드 추가하고 빌드 하고 확인하고 하는것을 계속 반복하는걸 구경하고 있었는데… 나름대로의 결론을 낼 수 있었다.
- qwen3-coder 보다는 훨씬 오류를 잘 찾는다.
- 생성되는 코드의 품질이 매우 낮다. 진짜 걸레같은 코드를 찍어낸다 claude, codex, gemini 는 그럭저럭 깔끔한 코드를 찍어내서, 별로 안 중요한 부분이거나 급할 경우 그냥 코드를 써도 될 경우가 많은데 glm 은 정말 지저분한 코드를 만들어 낸다.
- 기본적인 응답속도는 qwen 보다도 빠르다. claude 와 비교하면 꽤나 빠르다
- 2번에 이어 type 오류, var/val 가 잘못 생성되는 경우가 극히 많다. 나는 사용하지 않지만 weak type 언어(python, js 등 …) 를 사용 하는 경우 더 괜찮은 코드를 만들지, 아니면 오류가 숨겨진 코드를 생성 해 낼 지는 모르겠다
- 2~4 번의 결과로 혼자서 코드 찍고, 빌드 오류 체크하고… 빌드 -> 수정 -> 평가 -> 빌드 -> 수정 -> 평가 … 를 무한히 반복하다보니 결과적으로 프롬포트가 완료 되는데는 claude 대비 훨씬 오랜 시간이 걸렸다
- 한국어로 하라고 강조 하니, 일단 내가 읽어야 하는 메시지는 전부 한국어로 잘 나왔다
문서는 qwen3 으로도 충분히 쓸만한 결과가 나왔기에 이 모델을 별도로 테스트 하지는 않았다.
그리고 처음에 왠지 잘 되는 것 같아서 회사에서 쓰던 것 처럼 한번 해보려고 했는데… 아뿔싸 내 pc 는 한 대라는 것을 망각하고 있었다. 뭘 요청하던 그냥 GPU 는 계속 100%를 찍고 있다. 팬이 풀스피드로 돌아가는 속도도 시끄럽다 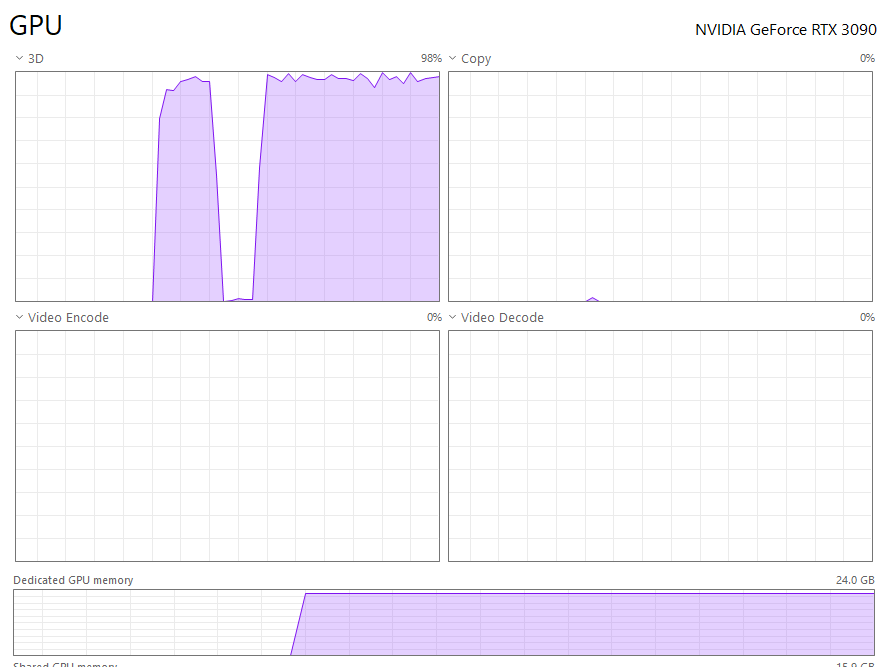
서버를 빌려서 쓰는게 아니고 모든 동작이 내 pc 에서 돌아가야 하는 이상 claude 를 쓸 때 처럼 동시에 여러 작업을 진행 할 경우, 그냥 모든 작업이 느려질 뿐이다. 딱 1개를 돌릴 때만 HW 를 독점 하고 있으니(모델이 작기도 하고) 빠른거라는걸 잊지 말자