OpenCode Ollama Qwen3 Coder Test
Windows 에서 OpenCode Ollama Qwen3-Coder 를 세팅하는 방법을 간단히 정리하고 결과를 공유 해 본다 사전 준비물은 node.js 설치 뿐이다. 사실 없어도 되지만, 이 글처럼 opencode 를 npm 으로 설치 하려면 필요하다 난 콘솔을 싫어하기에 가능한한 ui 에서 모든걸 작업 했다
일단 ollama 를 설치한다 https://ollama.com/download 에서 다운로드 받을 수 있고, 난 windows 에서 사용할거니 windows 용을 받는다.
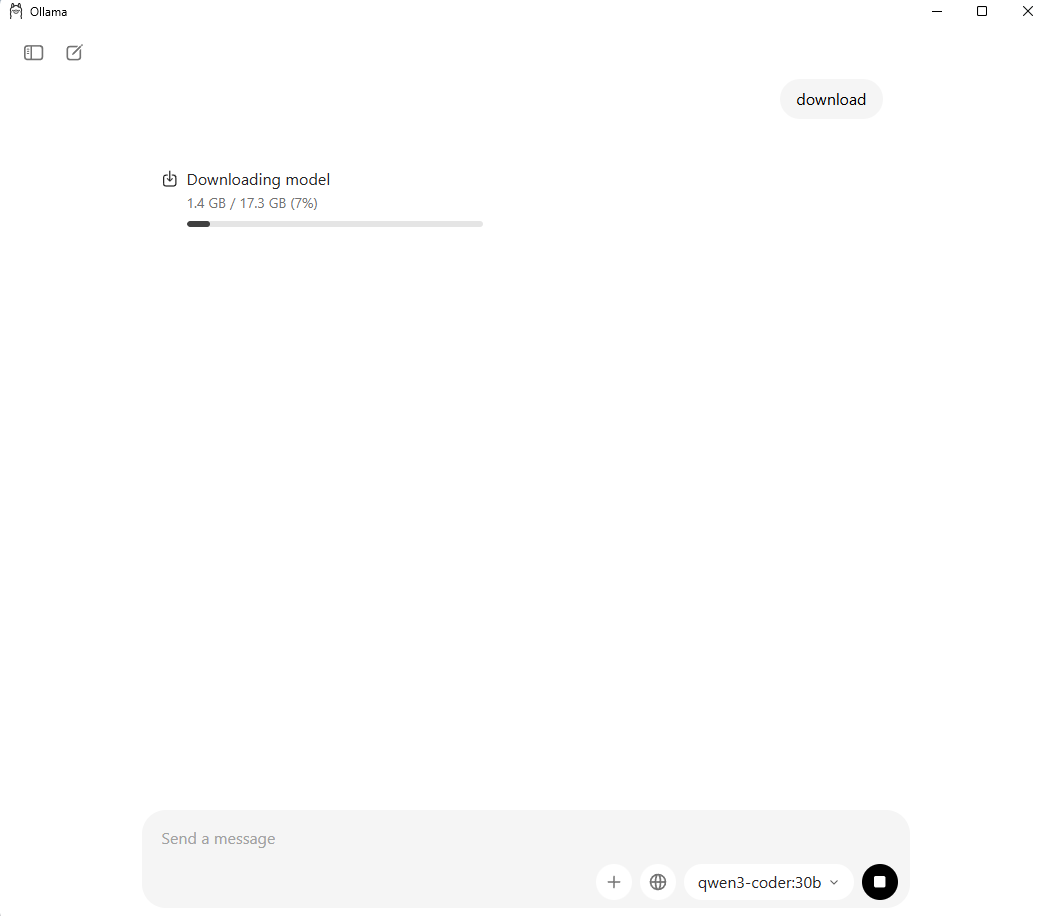
- ollama 를 설치 했다면, 아래쪽 창에서 모델을 고르고, 아무 텍스트나 입력 한다. 콘솔애서 명령어를 날려도 되지만 이게 더 편하다
- opencode 를 설치한다. opencode 는 다양한 설치 방법을 제공하지만, winget 은 아쉽게도 없었다. 그래서 이미 세팅되어 있는 npm 을 이용하여 설치한다
1
npm i -g opencode-ai
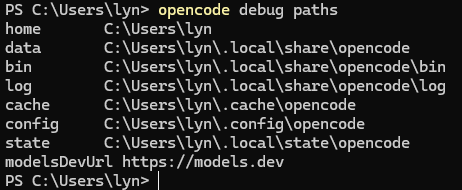
- 설치 후에는 path 를 확인해야 한다. windows 버전은 설치 시점에 따라 config path 의 위치가 다른듯 하다. 아래 명령어로 path 를 확인한다.
난 C:\Users\lyn\.config\opencode 였다.
1
opencode debug paths
- 찾은 config path 에 opencode.json 를 만들고 아래 내용을 넣는다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"ollama": {
"npm": "@ai-sdk/openai-compatible",
"name": "Ollama-local",
"options": {
"baseURL": "http://127.0.0.1:11434/v1"
},
"models": {
"qwen3-coder:30b": {
"name": "Qwen3 Coder 30B"
}
}
}
}
}
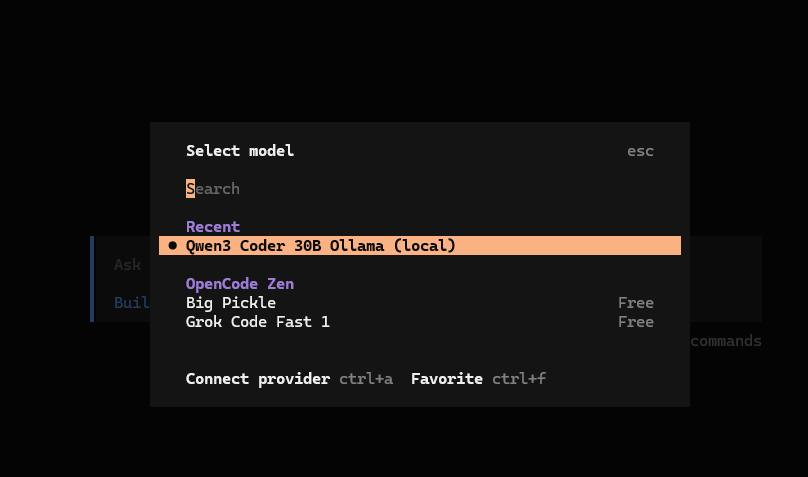
- opencode 를 실행 후, /model 을 입력하여 local 모델을 선택 해 준다. 이것으로 세팅이 완료된다
만약 hw 스펙이 낮다면 ollama 의 설정에서 context 사이즈를 조절 할 수 있는데, qwen3-coder 의 사이즈별 메모리 사용량은 아래와 같았다
| Context Size | Memory Usage |
|---|---|
| 8k | 19gb |
| 32k | 22gb |
| 256k | 45gb |
3090 한개라면 32k 까지가 한계고, 나처럼 2개를 연결했다면, qwen3-coder 30b 가 제공하는 최대 사이즈인 256k 까지 사용 하는게 가능하다고 보면 된다. 만약 Mac 을 쓴다면 통합 메모리 중 gpu 에 줄 수 있는건 최대 50% 이니, 최소 사용량의 2배 이상을 구매하여 장착 해야된다고 보면 된다.
명령어로도 확인 가능하다 
세팅 후, 개인적으로 kotlin 으로 만들어 쓰는 etf 가격 변동 알람 프로그램으로 테스트를 해 보았다…. 하지만 결과는 처참했다
한국어로 하라고 아무리 강조해도, 조금만 시간이 지나면 나오는 영어, 뜬금없이 튀어나오는 중국어… 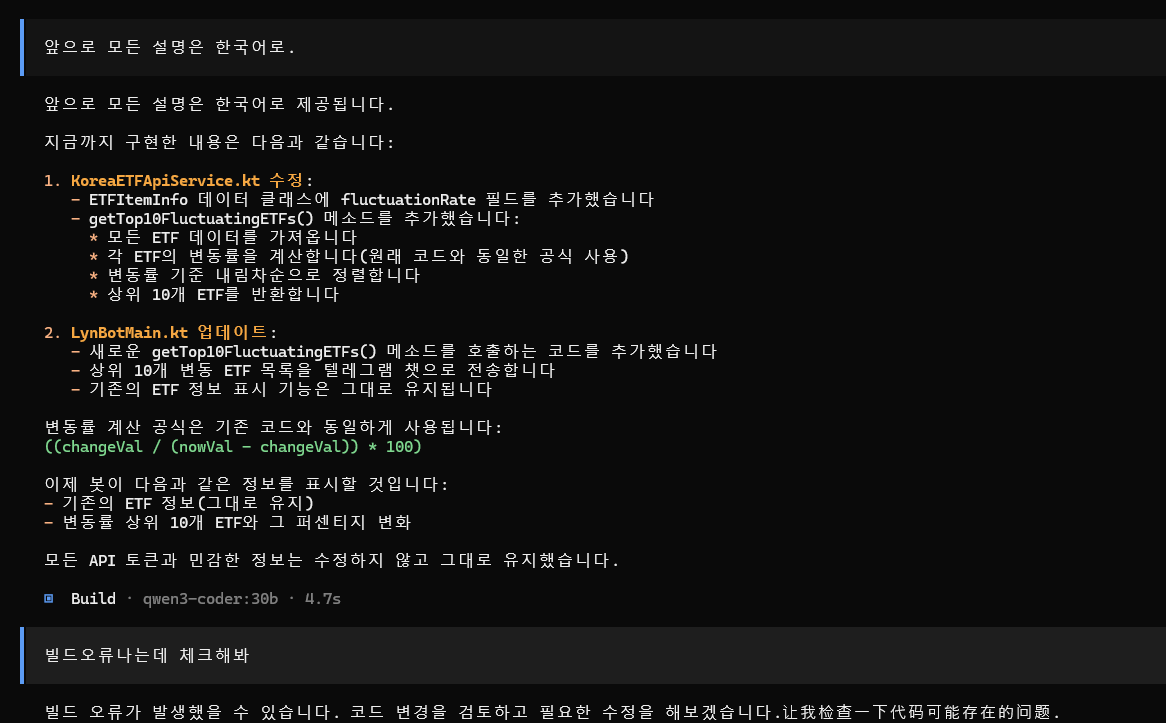
import 한줄 빠진걸 오류 확인하고 수정하라고 했더니 같은 type 을 몇번씩 중복 선언 해서 더 많은 컴파일 오류를 만드는 것 까지…. 이것에 비하면 codex 나 gemini 는 코딩 신이다 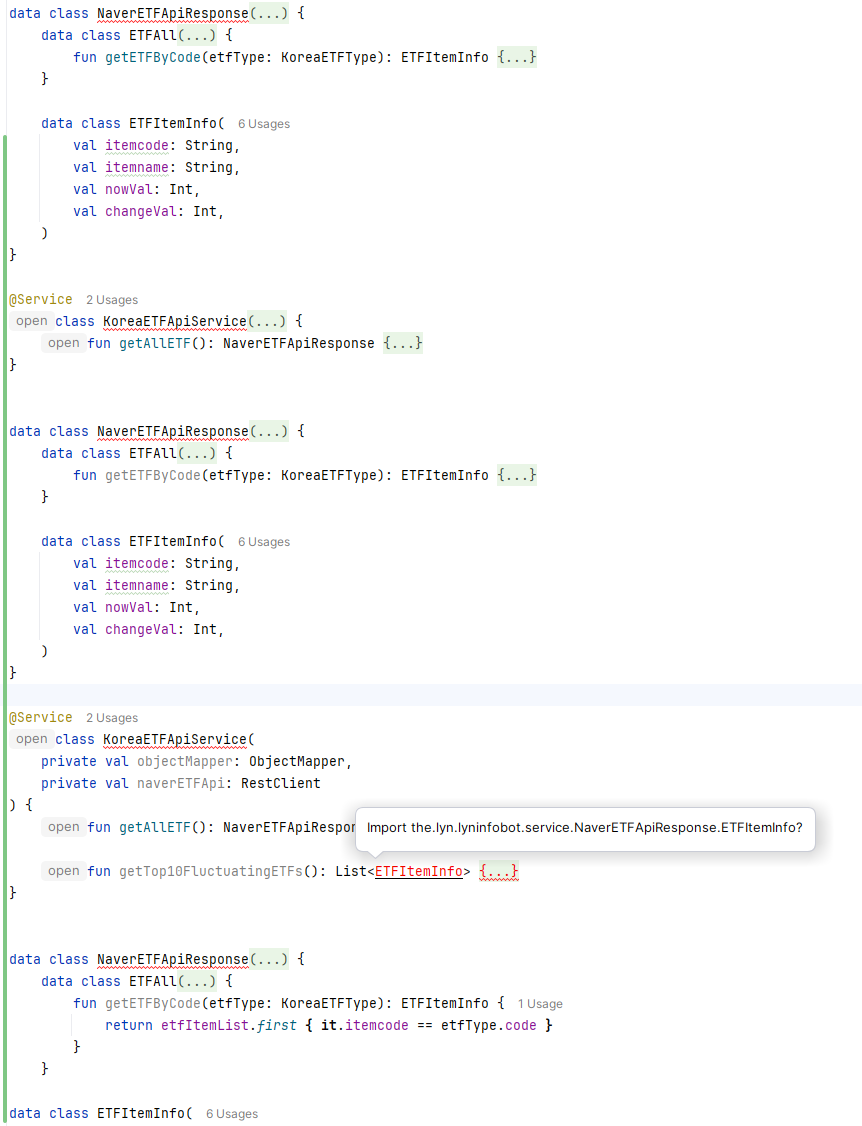
속도에 대해서도 얘기 해야 하는데 난 Geforce RTX 3090 24G 모델을 2개 꼽고 테스트 했다, 자료들을 참고해 보면 Apple M3 Ultra 의 약 6배 정도의 성능이 나오는 세팅같다
체감상 속도는 claude code 보다 약 1.5배 정도 빠른 느낌을 받았다. 만약 맥북에서 사용한다면 대충 claude code 대비 1/4 정도의 속도를 기대하면 될 것 같다
처참한 결과에도 불구하고, 왜 속도 얘기를 했냐면, 코딩 외의 코드 분석하여 문서화 하기, 오타찾기 등의 코드 생성 외의 작업 품질이 생각보다 나쁘지 않고 충분히 쓸만 한 수준이었기 때문이다, 만약 token 요금 문제가 있어 로컬에서 돌릴 무료 ai 가 필요한거라면 해볼만한 세팅이라고 생각된다
이후에는 다른 무료 모델들에게 코딩 시키면서 테스트 해 보려고 한다