C++ STL performance example with shared_ptr
시작하기 전에
이 말만은 하고 넘어 가야겠다… 이런 수준의 최적화나 성능이 필요 없는 프로젝트라서 STL 을 그냥 쓰는게 괜찮다고 생각 한다면 다시 한번 생각해라.
당신의 프로젝트는 Non GC Native 언어를 쓰기 적합한 프로젝트가 아닐 가능성이 높다, VM 기반의 언어로 교체 하기를 추천한다. 나도 99%의 프로젝트에는 더 이상 C++을 사용 하지 않는다. 대부분 C#, Kotlin, TypeScript 로 해결한다.
그리고 Non GC Native 언어가 꼭 필요한 프로젝트이고, 신규 프로젝트일 경우 가능하다면 Rust 로 대체하길 권한다. 비교적 높은 안정성을 C++ 과 맞먹는 속도로 챙길 수 있다.
현재 내PC 에서 한달에 한번 이상 켜서 사용하는 SW 중, C++로 작성 된 SW는 OS와 WebBrowser, KakaoTalk 달랑 세개 뿐이더라… 오히려 Javascript로 만든 SW가 더 많을 판이다. 당장 이 글도 JS로 만든 vscode 로 작성중이고…
아 게임은 빼고. 게임은 아직 C++의 점유율이 꽤 높다. C++ 게임 엔진들은 대부분(요즘 많이 쓰는 Unreal 4/5도 마찬가지다. Frostbite의 경우 자신들이 사용하는 EASTL을 인터넷에 공개해 두었다) STL 을 쓰지 않고 자체적인 라이브러리를 제공 하기 때문에 대부분의 프로젝트가 이 글에서 이야기 하는 수준의 최적화에 신경 쓴 프로젝트라 볼 수 있다.
최적화의 필요성
일단 편의를 위해 모든 코드는 내가 가지고 있는 i9-12900K CPU 에서 현재 기준 최신의 Visual C++ 2022 17.4.2 x64 에서 테스트 하였다.
C++의 표준 라이브러리는 STL 이다. 하지만 STL 은 C++ 의 컨셉에 걸맞게 극한의 범용성을 추구한 형태의 굉장한 고기능 라이브러리 이다. 반대로 이야기 하면 99% 의 유저는 사용 하지 않을 기능으로 가득하다는 거다. 물론 보통은 사용하지 않는 기능이 아무리 있어봐야 성능엔 영향을 주지는 않지만, STL 은 그 기능을 위해 구조상의 오버헤드를 많이 짊어지고 있다보니 꽤 느린편이다…
그 중 많이 쓰지만 구조상 무겁고, 안쓰는 기능이 많으며, 제일 간단하게 교체할 수 있는 라이브러리가 난 shared_ptr 이라고 생각 한다. 사실 string도 드럽게 구린데… 스펙상 Copy-On-Write 를 사용할 수 없기 때문이다. 대부분의 다른 언어의 String 구현은 COW 를 이용하는데… 하지만 그건 의존하는 라이브러리가 너무 많아 교체가 쉽지 않은게 현실이라 거기까지 가면 정말 노력을 많이 한 케이스겠다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
#include <memory>
void* operator new(std::size_t s) throw(std::bad_alloc)
{
printf("Alloc : %llubyte\n", s);
return malloc(s);
}
void operator delete(void* p) throw()
{
free(p);
}
class TestClass
{
public:
char arr[1024];
};
void main()
{
//std::make_shared
printf("Normal Alloc\n");
auto testClass = new TestClass();
printf("MakeShared\n");
auto sptr_1 = std::make_shared<TestClass>();
printf("New & Assign SharedPtr\n");
std::shared_ptr<TestClass> sptr_2(new TestClass());
}
위 코드를 실행 한 결과는 아래와 같다
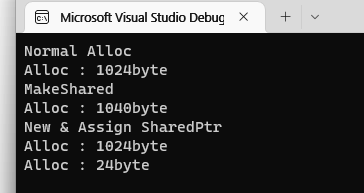
보면 알겠지만, std::shared_ptr<TestClass> sptr_2(new TestClass()); 와 같이 사용 할 경우 할당이 2번 일어난다. 그리고 std::make_shared 를 사용 할 경우 할당 사이즈가 달라진다.
이것이 극한의 범용성을 추구한 결과이다. 임의의 객체를 스마트포인터로 관리 할 수 있게 하기 위해(특정 객체의 상속이나 Mixin 없이), Reference Count 변수를 객체가 가지고 있어야 한다는 언어상의 제약이 없다. 그렇기 때문에 Heap 에 Count 를 관리할 별도의 공간을 확보해야 하고, 그걸 위해 make_shared 를 사용할 경우 추가 공간을 할당받아 카운터를 저장하고, new 로 반든 포인터를 shared_ptr 로 관리를 시작할 경우 별도의 공간을 할당 하기 위해 alloc 이 한번 더 일어나게 된다. 당연히 make_shared 와 new + shared_ptr assign 에 성능 차이가 발생 하게 되지만… 역시나 극한의 범용성, 모든 포인터를 shared_ptr 로 관리 할 수 있다는 정책을 지키기 위해 성능이 감소 될 여지를 두게 된다. 그리고 하나의 shared_ptr 객체에서 Reference Count 가 별도의 Heap 에 있을 때와 같은 Block 에 있을때 양쪽을 처리 하기 위해 Reference Count 용 변수를 Pointing 하고 있는 변수를 추가하여 가르키게 해야 한다. 즉 shared_ptr의 대입 시 추가적인 대입이 한번 더 일어난다
다음 문제는 shared_ptr 구조상 절대 해결 되지 않는 퍼포먼스 하락 이슈이다. 그것은 바로 weak_ptr 의 지원이다. 혹시 프로젝트에서 weak_ptr 를 써 본 적이 있는가? 난 2005년부터 대형 C++ 프로젝트를(OS나 WebBrowser 같은 초대형은 아니다…) 많이 해 왔지만 weak_ptr 를 유용하게 써 본적이 전혀 없다. 많은 경우 순환 참조를 이야기 하는데, 난 개인적으로 순환참조는 설계 상의 미스라고 생각한다. 웹 개발시 흔히들 많이 쓰는 Spring Framework 같은 경우도 순환참조를 발견 시 BeanCurrentlyInCreationException 가 발생한다.
하지만 shared_ptr 는 weak_ptr를 사용 하든 안하든 일단 스펙상 지원을 하고 있기 때문에 한번의 대입/해제시 카운트가 2번씩 바뀐다. Shared Count 와 Weak Count 를 따로 가지고 있고, shared_ptr 이 복제될때는 둘 모두 atomic inc, weak_ptr 이 복제될때는 Weak Count 만 atomic inc 하는 방식이다. 단순하게 이야기 해서 shared_ptr를 weak_ptr 지원 없이 없이 재구현 할 경우 성능을 올릴 수 있단 이야기이다. 당연히 Reference Count 를 저장한 메모리는 Weak Count 를 위해 끝까지 살아 있어야 하므로, Weak Count 가 없어질때 까지 해당 메모리는 살아 있게 된다.
단순히 대입성능만을 체크 하기 위해 다음과 같은 코드로 최소한의 구현만 된 새로운 스마트 포인터와 성능을 비교 해 보았다. 뭐 내가 실제로 쓰는 구현도 여기서 크게 다르지 않다. 편의성을 위한 연산자나 레퍼런스카운팅을 하지 않는 Wrapping Pointer 를 위한 지원이 조금 추가 된 정도지
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
#include <memory>
#include <windows.h>
void* operator new(std::size_t s) throw(std::bad_alloc)
{
printf("Alloc Size : %llu\n", s);
return malloc(s);
}
void operator delete(void* p) throw()
{
printf("Delete : %p\n", p);
free(p);
}
class TestClass
{
public:
char arr[1024];
};
class TestClass2
{
private:
volatile intptr_t referenceCount = 0;
public:
__forceinline int dec()
{
return _InterlockedDecrement64(&referenceCount);
}
__forceinline int inc()
{
return _InterlockedIncrement64(&referenceCount);
}
char arr[1024];
};
template <typename T>
struct my_shared_ptr
{
T* object;
my_shared_ptr(T* t)
{
t->inc();
object = t;
}
~my_shared_ptr()
{
if (object->dec() == 0)
{
delete object;
}
}
my_shared_ptr(const my_shared_ptr<T>& ptr)
{
ptr.object->inc();
object = ptr.object;
}
};
void main()
{
int loopCount = 1000000000;
{
printf("MakeShared\n");
auto startTick = GetTickCount64();
auto sptr = std::make_shared<TestClass>();
for (int i = 0; i < loopCount; ++i)
{
auto p = sptr;
}
auto endTick = GetTickCount64();
printf("Time :%llums\n", endTick - startTick);
}
{
printf("InHouse Shared\n");
auto startTick = GetTickCount64();
my_shared_ptr<TestClass2> iptr(new TestClass2());
for (int i = 0; i < loopCount; ++i)
{
auto p = iptr;
}
auto endTick = GetTickCount64();
printf("Time :%llums\n", endTick - startTick);
}
}
최적화를 모두 켜고 작동 시킨 결과이다
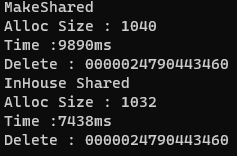
24% 정도의 성능 향상을 볼 수 있다.
그리고 STL로 대형 C++ 프로젝트를 하면서 가장 문제가 되었던 것이… 디버깅을 위해 최적화를 끄고 실행 할 경우 도저히 테스트가 불가능할 정도로 SW가 느려지는 경우가 많다는 것이다. 특히 게임이 그렇다… 그 이유는 간단한 것이, STL 소스를 보면 알겠지만, 엄청나게 Call Depth 가 깊은 것을 볼 수 있다. 이것은 STL 자체가 강력한 C++ 컴파일러 최적화를 믿고, 컴파일러에 의존하여 성능을 내고 있기 때문이다. 알만한 사람은 알 이 글을 쓰게 된 원래 이슈였던 코드를 최적화 하기위해 코드를 지저분하게 만드는걸 까는 건을 다시 한번 언급하자면 최신 컴파일러의 최적화 능력은 정말 대단하다.
하지만 디버깅 할 때는 얘기가 살짝 달라지는데, STL 같은 라이브러리는 최적화 기능을 끄는순간 성능이 극단적으로 떨어진다. 하지만 InHouse 라이브러리라면 코드를 극히 간단하게 만들 수 있으므로, 최적화가 없어도 속도가 떨어지는 정도가 비교적 적다. 프로젝트가 디버깅 시의 퍼포먼스가 어느정도 중요 할 정도로 크다면 가치가 좀 더 생긴다 볼 수 있겠다. 그런 의미에서 최적화를 끈 debug 모드에서의 비교를 보자.
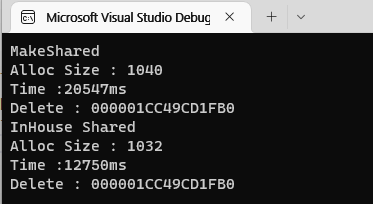
약 38% 정도의 성능 향상을 볼 수 있다. 무거운 상황에서의 디버깅을 자주 해야 하는 경우라면 좀 더 의미가 있다고 할 수 있겠다.
위의 코드들은 Loop가 Performance 를 추가적으로 잡아먹었기 때문에, 실제로는 차이가 좀 더 벌어질 것이다… Unreal5 의 경우 한발 더 나가서 Thread Safe 하지 않은 Smart Pointer 도 제공 하는데, 난 일단 서버가 주 업무이기도 하고 포인터 종류까지 구별해가면서 쓰는건 완전 오버라고 생각 하기 때문에 도입하지 않았다.
결론적으로 SW 에서 진짜 미친듯이 발생하는 레퍼런스 카운팅이라는 연산이 원래는 Assign 한번 + Atomic 한번 으로 될 작업이었지만, shared_ptr 를 쓰는 순간 Assign 두번 + Atomic 두번 으로 무거워 지는거다. 그리고 프로젝트 전체에서 메모리 모니터링 같은 기능을 넣기 위해서도 아무래도 shared_ptr 보다는 자체 구현이 편한, 성능하고 관계 없는 장점도 있다… hot spot 은 아니지만 복잡한 라이브러리가 아닌 경우 교체만으로 SW 전체의 퍼포먼스를 간단히 올릴 수 있기 때문에 해볼만 한 최적화라 할 수 있다. 난 개인적으로 Chromium 프로젝트에 구현된 Smart Pointer 를 가져다 쓰는 편인데, boost 를 사용 할 경우 intrusive_ptr 로도 대체할 수 있겠다.
PS. make_shared와 assign 의 할당 구조가 다르다는걸 알려주신 트위터의 이름모를 분에게 감사를. 내가 TR1 시절에 봤을땐 똑같았던걸로 기억 하는데.. 언제 달라졋대
PS2. 난 실제로 2008년 쯤 서버에서 쓰고 있던 std 컨테이너와 string 을 모두 mfc 의 것으로 바꾸는 것 만으로 40% 이상의 cpu 점유율 감소를 본 적이 있다. 그때는 C++에 RValue Reference 가 도입되기 전이라 지금보다 성능 향상이 좀 극적이긴 했다…
PS3. 나 C++ 안쓴지 5년도 넘었는데 이글 왜썼지. 이거 쓸려고 VC++ 설치했다
PS4. 난 vector 도 교체 해 본적이 있는데… vector 의 제약중 하나인 모든 원소의 메모리가 연속적으로 할당 되어야 한다는 조건을 빼버리면 원소 갯수가 증가 하여 재할당과 복사가 필요한 경우를 배제할 수 있기 때문에, 성능이 굉장히 좋은(아무리 늘어도 복사를 안해도 되니까…) dynamic size array를 만들 수 있다. 하지만 그땐 특수목적용으로 그 부분의 성능이 굉장히 중요했던 경우라 추천은 하지 않음… 메모리 넉넉하면 걍 reserve 크게 해놓고 쓰면 된다